AI
Product
9 Min.
Literature Searches: Streamlining Human Study Detection

Shailza Jolly
Mar 29, 2025
Johannes Leitner
Mar 29, 2025

The Challenge of Identifying Human Studies
For medical device manufacturers, regulatory compliance isn’t just a box to check. It’s a constant challenge. Every device on the market must be backed by scientific evidence, proving both safety and effectiveness. But identifying the right studies, those that involve human subjects, is easier said than done. Reading through thousands of abstracts, only to find that many focus on animals, plants, or in vitro models, is an inefficient and time-consuming process. And while PubMed does offer a filter for human studies, it’s far from perfect, achieving only 80 % precision. This means that significant non-human studies still slip through, requiring manual screening to separate relevant research from irrelevant data.
And this is where we come in: At Flinn.ai, we’ve developed an automated abstract screening filter that excludes all non-human studies with 99 % precision. By leveraging the power of Large Language Models (LLMs), we streamline the literature review process, allowing manufacturers to focus on the studies that truly matter, saving time, reducing manual workload, and ensuring a more efficient regulatory workflow.
In this article, we dive into the challenges of identifying human studies — a task that may seem straightforward at first glance but often proves surprisingly complex for both human experts and AI models. We examine why these difficulties arise, how our approach overcomes them, and the tangible benefits it offers to medical device manufacturers looking to streamline their literature review process. Ready?
Cutting Through the Noise in Literature Searches
First things first: We use the title and the abstract of a scientific publication as an input and classify these inputs as human-study and non-human-study. Here is a sample title and abstract from a human study:

At Flinn.ai, we’ve built a filter to streamline this process. Instead of wasting time screening irrelevant studies, our system automatically detects and removes non-human studies, ensuring that only relevant, human-based research appears in your search results. With a focus on 100% precision, our system minimizes the risk of false exclusions, meaning you can trust that when a study is filtered out, it truly doesn’t belong.
To ensure the highest level of precision, we approach this challenge as a multiclass classification problem, designed to accurately distinguish human studies from non-human ones. Instead of a simple yes-or-no system, we introduce three distinct categories: yes, no, and unsure. This allows for greater accuracy in cases where ambiguity arises. Here’s how we define each class:
Human Study
Explicitly mentions humans (e.g., "patients", "participants", "clinical trial").
Mentions humans alongside animals/plants/microbes (e.g., "human and mouse models").
Study design implies human involvement (e.g., "randomized controlled trial", "in vivo human data").
Non-Human Study
Exclusively focuses on animals, plants, microbes, insects, etc. (e.g., "in mice", "cell cultures", "Drosophila").
No mention of humans or human-derived data.
Unsure
Ambiguous language (e.g., "subjects", "samples" without specifying human/non-human).
Theoretical/mechanistic studies (e.g., "molecular pathways", "in silico modeling") with no clear participants.
The following abstract serves as an example categorized as "Unsure”:

Methodology
Building the Dataset: A Deep Dive
Our dataset consists of 1,123 pairs of scientific titles and abstracts, each hand labeled as human study: Yes, No and Unsure. The Unsure category was necessary for handling cases where abstracts use vague language or involve both human and non-human elements, making classification challenging. Many studies fail to clearly specify human involvement, creating difficulties even for experts.
Data Collection: The Challenges of Existing Database Filters
We sourced our dataset from PubMed, one of the largest biomedical literature databases, using two Boolean queries:
A query containing the "Animals" MeSH term, which retrieved only 10 % of animal studies — demonstrating that relying solely on MeSH terms would leave many non-human studies undetected.
A second query using "Animals" AND NOT "Humans", which retrieved 80 % of animal studies — indicating that PubMed’s default categorization still allowed significant overlap.
Key Takeaways from Data Collection
PubMed’s MeSH terms alone are inappropriate for filtering non-human studies - applying them would exclude too many relevant human studies.
Our users’ search results differ from ours - we intentionally created an experimental dataset, which includes studies on insects, plants, and viruses. Our users use more restrictive queries.
Our AI model’s precision is a lower bound - since our dataset contains many difficult edge cases, we expect the model to perform even better on real-world MedTech searches.
Data Splitting: Training, Validation, and Testing
To ensure our AI model delivers reliable and unbiased results, we split the dataset into three subsets:
Training Data - Used to train the machine learning model and provide a foundational understanding of study classification.
Validation Data - Used to fine-tune and optimize the model, ensuring it generalizes well beyond the training set and avoids overfitting.
Test Data - A completely unseen dataset used for final evaluation, ensuring the model performs accurately on new publications.
The table below reports the distribution of classes for the train, validation and test data. In the test data the number of non-human studies (column “No”) is by far the largest class.

Modeling: Training the Software to Classify Human vs. Non-Human Studies
Step 1: Leveraging Large Language Models (LLMs)
As a first step, we started by experimenting with multiple Large Language Models (LLMs), both open-source and proprietary, using:
Zero-shot prompting –The model makes predictions without prior examples, relying purely on its pre-trained knowledge.
Few-shot prompting – A small number of labeled examples are provided to help guide the model’s understanding.
Dynamic multi-shot prompting – The model adapts its approach by using multiple examples, refining its classification process in real time.
Prompting allows us to guide the AI without modifying its internal parameters, ensuring flexibility across different datasets. By carefully crafting instructions and providing real-world study examples, we helped the model identify key indicators of human involvement in scientific studies.
Step 2: Fine-Tuning for Precision
Next, we fine-tuned multiple open-source and proprietary LLMs using our training and validation data. Unlike prompting, fine-tuning adapts the model’s internal weights, allowing it to learn directly from our dataset.
Step 3: Interpreting AI Decisions
During the experiments, we generate the reasoning behind the LLM's classification along with the classification result. This approach allows us, despite not being domain experts, to assess whether the drop in accuracy is due to the LLM or to incorrect ground truth. The model with the highest accuracy on the test/validation data was a fine-tuned version of a pre-trained model – it’s also the model currently in use in Flinn.ai. In the next section, we take a closer look at the performance results.
Results: Measuring AI Performance in Literature Screening
Evaluating Model Performance
How do we ensure that our AI model reliably classifies human vs. non-human studies? By systematically evaluating its performance across key metrics:
Accuracy – How often the model’s predictions match the actual classification.
Precision – The percentage of studies classified as non-human that were correctly identified.
Recall – The ability of the model to find all relevant non-human studies.
One of our top priorities is ensuring that no relevant human studies are mistakenly filtered out. That’s why in addition to the three metrics, Precision non-human-study is also computed for the non-human studies.
Addressing the “Unsure” Factor
Large Language Models (LLMs) tend to assign the unsure label less frequently. To account for this, we implemented an additional metric:
Filtered-Precision-Non-Human-Study (Precision-no-F) – This metric removes unsure cases and calculates precision based only on clear-cut human and non-human classifications.

Real-World Results
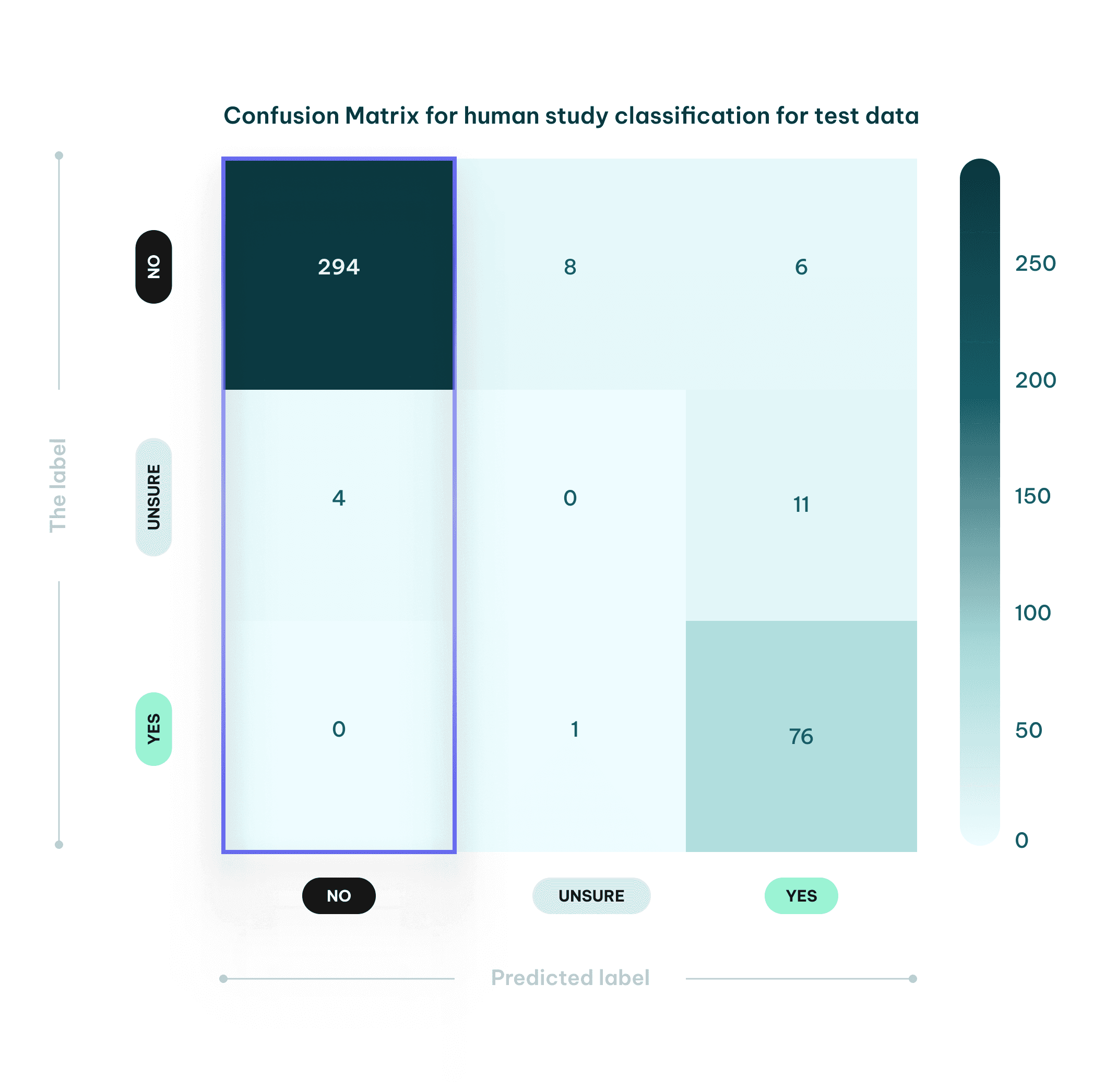
As reported in the confusion matrix below, our AI model classified 298 studies as non-human: 294 classifications were correct, 4 cases were marked as "Unsure" – these abstracts were too ambiguous, requiring full-text analysis for proper classification. These unsure cases are not filtered out and left for evaluation by the user.
Challenges in AI-Powered Literature Screening
Even the most advanced models face hurdles when classifying human vs. non-human studies. Two major challenges stand out:
Ambiguous and Unclear Abstracts
Scientific abstracts are not always written with clarity. Many studies use vague terminology or fail to explicitly state whether human subjects were involved. This creates edge cases where even human reviewers disagree on classification.
To tackle this, we brought in an additional domain expert to review misclassified cases.
Interestingly, the expert often sided with the AI’s classification rather than the original human annotations.
This suggests that the inherent subjectivity of scientific abstracts plays a significant role in classification challenges.
Dataset Limitations: The PubMed Gap
Our model was initially trained on data sourced from PubMed, using Boolean queries designed to capture non-human studies. However, this approach introduced a key discrepancy:
The dataset contained studies on plants, viruses, and insects, which are rarely relevant to MedTech manufacturers.
These unusual cases made classification harder, as many abstracts did not fit the standard categories seen in real-world literature screening – we anticipate that our model will perform better on customer data, where such edge cases are likely to be less frequent.
Flinn.ai: Where We Are At
For this model, our goal was the detection of human studies for abstract screening – and by leveraging Large Language Models (LLMs), we’ve significantly reduced the manual workload, enhanced precision, and streamlined the abstract screening process.
Up to 30% faster abstract screening – Our approach allows users to efficiently filter out non-human studies, saving valuable time and effort.
99% precision – On PubMed datasets, our model has demonstrated near-perfect accuracy in detecting non-human studies.
Improved compliance and efficiency – Automating literature screening reduces human error and ensures that critical human studies aren’t overlooked.
… And What’s Next?
Glad you asked! Our next steps include:
Expanding to full-text analysis – Incorporating open-access papers will enable higher precision by considering complete study details rather than just abstracts.
Refining AI with real-world MedTech data – Training on industry-specific datasets will further improve relevance and accuracy.
Enhancing usability and customization – Optimizing AI features to better align with different user needs and regulatory requirements.
With increasing regulatory demands, the need for fast, accurate literature screening has never been greater – ready to streamline your literature review process? Let’s talk!













